https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-4462760071454301Assignment 1: Written Assessment
Weighting: 35%
Assessment Task:
This is an individual assessment.
In this assessment, you are required to choose one of the following industries: Healthcare, Insurance, Retailing, Marketing, Finance, Human resources, Manufacturing, Telecommunications, or Travel. This assessment consists of two parts as follows:
Part A – You are required to prepare a report on how Big Data could create opportunities and help the value creation process for your chosen industry.
Part B – You need to identify at least one dataset relevant to the industry and describe what opportunities it could create by using this dataset.
In Part A, you will describe what new business insights you could gain from Big Data, how Big Data could help you to optimize your business, how you could leverage Big Data to create new revenue opportunities for your industry, and how you could use Big Data to transform your industry to introduce new services into new markets. Moreover, you will need to elaborate on how you can leverage four big data business drivers- structured, unstructured, low latency data, and predictive analytics to create value for your industry. You are also required to use Porter’s Value Chain Analysis model and Porter’s Five Forces Analysis model to identify how the four big data business drivers could impact your business initiatives.
In Part B, among several open source and real-life datasets, you will identify at least one dataset that is relevant to the industry you had chosen. The dataset can be a collection of structured, unstructured or semi-structured data. Using this dataset, you will first discuss how you chose this dataset among other datasets. Then, you will identify and present the metadata of the dataset. Using the chosen dataset, you will need to describe the opportunities it could create for the chosen industry.
The length of the report should be around 2500 words. You are required to do extensive reading of more than 10 articles relevant to Big Data business impacts, opportunities and value creation process. You need to provide in-text referencing of chosen articles.
Your target audience is executive business people who have extensive business experience but limited ICT knowledge. They would like to be informed as to how new Big Data technologies might be beneficial to their business. Please note that a standard report structure, including an executive summary, must be adhered to.
The main body of the report should include (but not limited to) the following topics:
1. Big Data Opportunities
2. Value Creation using Big Data
3. Porter’s Value Chain Analysis
4. Porter’s Five Forces Analysis
The length of the report should be around 2500 words. You are required to do extensive reading of more than 10 articles relevant to Big Data business impacts, opportunities, and value creation processes. You need to provide in-text referencing of chosen articles.
Your report must have a Cover page (Student name, Student Id, Unit Id, Campus, Lecturer and Tutor name) and a Table of Contents (this should be MS word generated).
Caution: ALL assessment submissions will be checked for plagiarism by Turnitin.
Assessment Submission:
You must upload the written report to Moodle as a Microsoft Office Word file by the above due date.
Assessment Criteria:
You will be assessed based on your ability to analyse and reflect on how organisations are leveraging non-traditional valuable data (unstructured, real-time) with the traditional enterprise data (structured) for business intelligence and value creation. The marking criteria for this assessment are as follows.
Part A (25 marks):
Executive Summary – 3 marks
Table of Contents – 1 mark
Introduction – 2 marks
Big Data Opportunities – 4 marks
Value Creation using Big Data – 4 marks
Porter’s Value Chain Analysis – 4 marks
Porter’s Five Forces Analysis – 3 marks
Conclusion – 2 marks
References – 2 marks
Part B (10 marks):
Dataset identification – 2 marks
Metadata of the chosen dataset – 3 marks
Business opportunities through the chosen dataset – 5 marks
Answer———————————————————————————————–
COIT20253: Business Intelligence using Big Data
Assessment 1
Business Intelligence using Big Data
Link for the data sets– https://www.kaggle.com/rashikrahmanpritom/heart-attack-analysis-prediction-dataset
EXECUTIVE SUMMARY
https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-4462760071454301This report is about big data in the health care industry, how big data has helped in the health care industry, changing the lives of people, improvising business opportunities, and creating a value chain for wellbeing. The affiliated element data incorporates the center watchwords essentially found in wellbeing huge information and their acquainted catchphrases. For the assortment of wellbeing reports, Web pages were examined and different articles were searched for the correct dataset to validate the report (Cheryl Ann Alexander and Lidong Wang, 2017). Different techniques have been presented to clarify big data opportunities and benefits in the health care industry
Contents
2.1 Advantages of Big Data in Health Care
2.1.4 Information Visualization
3.0 Importance of Big Data in Health Care
3.1 Arrangement of driven administrations to patients
3.2 Identifying spreading infections prior
3.3 Adjusting the treatment methods
4.0 Value Creation of Big Data in health Care
4.4 Predictive analysistelemedicine
5.0 Porters Five Process Model for Health Care Industry
7.0 Metadata of the chosen Dataset
Business Opportunities of the chosen Dataset
Detection of Heart attack through wireless
1.0 Introduction
The healthcare industry is data-intensive and could use interactive dynamic big data platforms with innovative technologies and tools to advance patient care and services (Galetsi, Katsaliaki & Kumar 2020). To manage cardiovascular disease, we have to assess huge scores of datasets, think about and dig for data that can be utilized to anticipate, forestall, oversee and treat persistent sicknesses, for example, coronary episodes. Enormous Data examination, known in the corporate world for its important use in controlling, differentiating, and overseeing huge datasets can be applied with much accomplishment to the forecast, anticipation, the board, and treatment of cardiovascular illness (Alexander and Wang, 2017).
2.0 Big Data Opportunities
2.1 Advantages of Big Data in Health Care
Some advantages of big data over health care are listed below
2.1.1 Information Collection
This action requires the assortment of information through different illnesses like diabetes and so on the underlying sign are pulse, a circulatory strain which is estimated by ECG, EEG. There are numerous suppliers in the market for giving body sensors. Wellbeing signals are continually gotten from on-the-body or in-the-body sensors and accordingly scholarly by the cell phone (Kulkarni et al., 2020).
2.1.2 Information Extraction
Huge information investigation innovation is utilized to remove and dissect significant information and expected qualities from organized information, semi-organized information, and unstructured information that surpass the preparing scope of an overall data set administration framework. The term organized information alludes to the information saved in fixed fields, including social data sets and office data, semi-organized information alludes to information that incorporates metadata and blueprint, despite the fact that they are not saved in fixed fields, and unstructured information alludes to the information that are not saved in fixed fields, including text, video, voice, picture, and mixed media (Telemedicine and e-Health, 2020).
https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-44627600714543012.1.3 Modelling
Information digging apparatuses are utilized for prescient displaying which helps in the expectation of patterns and examples. In this sort of demonstration different indicators are utilized for anticipating different assortments of information.
2.1.4 Information Visualization
Information representation is an instinctive route for clients to effortlessly peruse and get information, particularly in huge information examinations. It assists with improving the nature of approaches or administrations by introducing a coordinated view and proof for settling on medical care choices (Ko and Chang, 2017).
It is likewise castoff in the prognostic examination which is to perceive and talk about the therapeutic issue before it turning into a wild issue. Medical care experts are skilled to diminish the threat and overpowered the issue with the material imitative from the huge information. Data Visualizations were utilized to morally return wellbeing information to low-wellbeing education patient populaces (Skiba, D.J., 2014).
3.0 Importance of Big Data in Health Care
3.1 Arrangement of driven administrations to patients
To convey faster guide to the patients by giving sign related medication recognizing indications and infections at the earlier stages that rely upon the clinical data possible, decreasing painkiller measurements to lessen result, and giving successful drug made on heritable makeup. These advantages in diminishing readmission degrees accordingly diminishing the rate for the patients.
3.2 Identifying spreading infections prior
Calculating the viral sicknesses preceding earlier dispersing made on the live examination. This can be perceived by assessing the local area logs of the patients upsetting from an ailment in a particular spot. This guides the medical care experts to coordinate the victims by having fundamental guarded systems. Noticing the clinic’s quality: To check whether the facilities are organized according to principles given by the Indian restorative gathering. It benefits the organization in checking fundamental activities in the logical inconsistency of restricting facilities.
3.3 Adjusting the treatment methods
The registration of the changed casualty tells the outcomes of meds continually and by these examinations amounts of prescriptions can be modified for fast outcomes. By checking patient’s enthusiastic signs to offer dynamic precautionary measures to patients, making an examination on the reports created by the patients who recently experienced comparable signs, helps the expert to convey genuine tablets to different casualties. Large information is progressively applying a significant impact on worldwide creation, flow, dispersion, utilization exercises, financial activity component, social way of life, and public administration limit (Guo and Chen, 2019)
4.0 Value Creation of Big Data in Health Care
4.1 Structured Data
The structured data in this dataset contains the patient’s data such as age, gender, and life habits. For doctors impervious to organized information catch, a crossbreed approach should be built up that mixes the capacity to catch required organized information components and gives doctors the adaptability to record in their very own way. This will expand doctor appropriation while meeting information detailing and information trade needs (Guest Blogger, 2011).
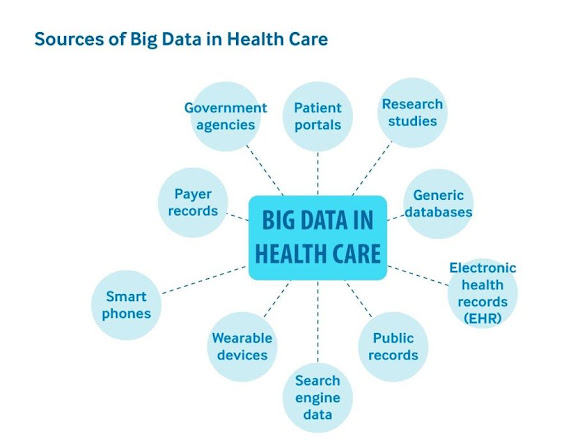
Figure 1: Structural data Sources of Big Data in Health Care
Source: (Bing.com, 2021)
4.2 Unstructured Data
The unstructured data consists of physician notes, x-ray images, diseases onset prediction, medical documentation, accuracy. Clinical diaries can be perused by machines to extricate the most significant data to be made accessible for suppliers. Contact focus specialist notes can be broke down to recognize drivers of positive or negative patient estimations and for distinguishing openings for decreasing call taking care of time, call volume, intelligent voice reaction nonconformist, and Repeat Calls. Doctor notes can be dug for readmission forecast, infection beginning expectation, clinical documentation exactness, and the sky is the limit from there. (Journal Of AHIMA, 2018)
4.3 low latency data
Low inactivity is requesting quick, predicable and deterministic reaction time as a business need. Monetary firms still presumably have the best requirement for ultra-low inertness, yet low inactivity is currently significant for some organizations, regardless of market. Associations are progressively getting enormous volumes of information across their organization and doing so rapidly and effectively is basic. Huge information and low inactivity are intensely connected. The expected worth of enormous information is colossal however it relies upon having the option to break down and get understanding from it progressively. The effect and significance of dormancy relies upon the particular application and accomplishing the least conceivable inactivity requires a compromise between other organization attributes. Having identified the significance of low dormancy in our large information foundation that offers exposed metal force for speed and execution, we made it a necessary piece of our contribution (Bigstep, 2013).
4.4 Predictive analysis
The expression “Predictive analysis” portrays a strategy of getting an understanding into the conceivable future occasions dependent on the accessible information and measurable investigation, addressing the inquiry “What may occur?”
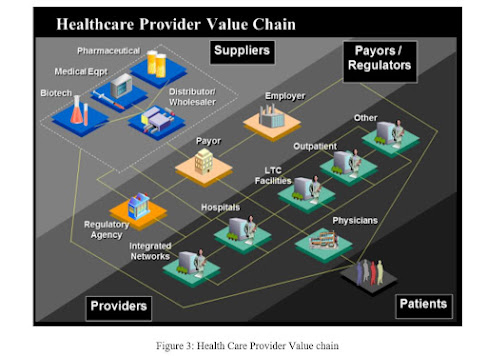
Figure 3: Health Care Provider Value chain
Source: (Hubspotusercontent30.net, 2021)
4.5 Practicing telemedicine
Telemedicine has been demonstrated to be particularly valuable in underserved networks where there is a lack of nonappearance of sufficient clinical consideration, for example, in far-off territories. Interestingly, in created and agricultural nations the same, demonstrated, dependable, and savvy telemedicine and telehealth administrations are accessible at scale. Subsequently, because of the vigorous empowering innovation foundation, the incredible guarantee of telemedicine has at last shown up. Maybe then move the patient to the clinical subject matter expert, it is currently ordinary to saddle the force of innovation to communicate the information on the expert right to the patient out of luck (Nittari et al., 2020).
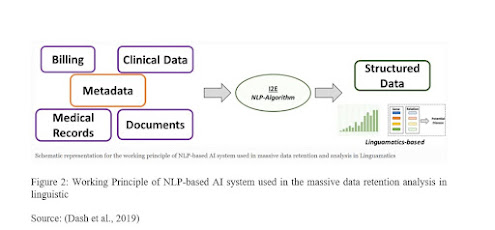
Figure 2: Working Principle of NLP-based AI system used in the massive data retention analysis in linguistic
Source: (Dash et al., 2019)
5.0 Porter Five Process Model for Health Care Industry
5.1 Competitors and New Entrant threat
Different healthcare companies lead in terms of margin over other companies from other health care companies showing fierce competition. Industries can gain a lot of benefits because of the competition as they can switch the cost of the medicine. An individual person can choose only one health care policy so they will use only one policy and not be able to switch between policies (Adamkasi, 2017).
5.1 Buyers Bargaining Power
Customers hold a weak bargaining power so they have a weak position to bargain. For availing of the health care service, a certain price has to be paid. Customers are bound to take the health insurance and pay the price because they can’t afford to pay the cost of life-saving operations if they get injured. So, according to Porter, Value generation is more important than price. This is the reason people choose high-standard health care facilities they can afford and the industry on the other hand gains margin from a value-based competition. Hence, the ultimate goal of the industry is to create enough value and establish a stable economic environment (Adamkasi, 2017).
5.2 Suppliers Bargaining Power
Suppliers stand a high position for bargaining as they are the ones who totally supply the goods to the health industry, being fewer in number than the consumers, they got enough demands from the people as well as the government sector (Adamkasi, 2017).
5.3 6Substitution of Existing Products
Customers always try to find the substitute of any products in terms of cost and quality, they prefer cheaper medicines and prescriptions. They visit different medical stores where they can find cheaper drugs however substitutes for complete health coverage plans and the situation is less alarming for future prospects (Adamkasi, 2017).
Customers at present like to adapt “do it yourself strategy” in this digital world most people want to adopt all the trends and want to be connected with the technology so they keep most of the medical equipment at home (Adamkasi, 2017).
Part B
6.0 Dataset Classification
The chosen dataset contains 14 columns and 304 rows of data information about health status report about heart attack analysis and prediction analysis. The dataset contains information about Age, sex, Chest pain and type of chest pain, resting blood pressure in mm hg, cholesterol level in the blood in mm hg, cholesterol in mg/dl fetched via Body Mass Index (BMI)of a person, fasting blood sugar, resting electrocardiographic results, maximum heart rate achieved, exercise included angina, and previous peak (Rashik Rahman, 2016)
7.0 Metadata of the chosen Dataset
The metadata for this dataset is provenance and the source is online got through the method crawling and the owner of the dataset is Rashmik Rahman where he updates the data annually. The dataset was created on 2021-3-22 and is version 2 of the analysis and the file format is in .csv format (Rashik Rahman, 2016).
8.0 Business Opportunities of the chosen Dataset
8.1 Detection of Heart attack through wireless
Cell phones and sensors can distinguish and send different wellbeing information. A wristwatch has been planned as Heart Attack Detection hardware utilized every day to demonstrate a heart condition, distinguish respiratory failure, and call for crisis help. Planned particularly for patients with coronary illness, it can diminish grimness and mortality as well as handicap too. The ECG is amazingly significant as a device for distinguishing coronary failure. ECG is an electrical chronicle of heart action and can be used in the examination of coronary illness. The wristwatch contains an ECG hardware unit that catches strange heartbeat signals from the patient. The microcontroller on the watch at that point runs a coronary episode calculation and the Bluetooth crisis calling framework dials clinical help during the hour of coronary episode. There will be two biosensors worn on the patient’s wrist which conveys the ECG message to the simple ECG hardware.
The enhanced and sifted simple yield of the hardware is made an interpretation of from simple to advanced sign and afterward communicated to the unit on the strolling watch. The ECG hardware unit, the A/D converter, and the transmitter are worn on one of the patient’s wrists. The watch is remote, giving the client more opportunity to move by keeping away from wires between the watch and the wrist. The patient wearing the watch gets an advanced ECG signal, and the microcontroller runs a respiratory failure calculation to recognize potential coronary episode indications. Assuming any side effect of a respiratory failure is identified, the danger level ascents. When a patient’s danger level arrives at the crisis mode, the Bluetooth module actuates the client’s cell phone to call 911 for clinical assistance. This can be a good scope of business as this is the current scenario most phones with these kinds of models are going for a good sell amount (Alexander and Wang, 2017).
8.2 Disease Forecasting and developing medicines using the Internet of Things
The Internet of Things (IoT) is a trendsetting innovation that exploits a few strengths like sensor advancement, the information obtained, the executives and handling, and correspondence and organizing were subjects (for example objects, individuals) with interesting attributes that can connect to a far-off worker and structure nearby organizations. Since the network in IoT-based frameworks grants objects to exchange, what’s more, combine information to acquire extensive information about their usefulness and characteristics of the adjoining conditions, it offers prevalent, canny, and efficient administrations. IoT innovations offer an improved personal satisfaction for people through nonstop (i.e., all day, every day) distant checking frameworks which is one of the essential highlights of this innovation.
Distant wellbeing checking turns out to be much more significant being taken care of by older patients because of the expanded feebleness also, vulnerability to different illnesses (for example intense and ongoing sicknesses) of mature age. Not exclusively does distant wellbeing observing improve the personal satisfaction of old patients, distinguishes and advises guardians and suppliers of crises, lessens nursing care needs and emergency clinic stays (for example medical services cost decrease), it can foresee and follow infection cycles, for example, respiratory failures (Alexander and Wang, 2017).
8.3 AYASDI
Ayasdi is one such large seller which centers around ML-based strategies to basically furnish machine insight stage alongside an application structure with attempted and tried Endeavor adaptability. It gives different applications to medical care examination, for instance, to comprehend and oversee clinical variety, and to change clinical consideration costs. It is equipped for breaking down and overseeing how medical clinics are coordinated, a discussion between specialists, hazard situated choices by specialists for therapy, and the consideration they convey to patients. It additionally gives an application to the appraisal and the board of populace wellbeing, a proactive procedure that goes past conventional danger investigation techniques. It utilizes ML insight for anticipating future danger directions, distinguishing hazard drivers, and giving answers for best results (Dash et al., 2019).

Figure 2: Intelligent Application Suite
Source: (Dash et al., 2019)
9.0 Conclusion
This report clarifies the importance of big data in the healthcare industry we have also studied the datasets and identified, what constraints were used to classify the data and to predict the future disease control and prevention methods and technologies that may help the upcoming generation to be alert on their health conditions. We have come to know the importance of big data in the health care industry how it could change the lives of people. This report contains the most recent data on Big Data examination in medical services, foreseeing cardiovascular failure, also, fitting clinical treatment to the person. The outcomes will control suppliers, medical care associations, attendants, what’s more, other treatment suppliers in utilizing Big Data advances to foresee and oversee cardiovascular failure just as what protection concerns face the utilization of Big Data examination in medical care. Viable and customized clinical treatment can be created utilizing these advancements. we can also know different business models and business values that could make this sector a big possibility in the future. Consequently, to permit the proficient administration and utilization of the archives, strategies have been initiated, and contemplates have been directed. In this paper, a technique for removing acquainted component data utilizing text mining from wellbeing large information was proposed.
Reference
Adamkasi (2017). Porter Five Forces Model of Health Care Industry|Porter Analysis. [online] Porter Analysis.
Alexander, C.A. and Wang, L., 2017. Big data analytics in heart attack prediction. J Nurs Care, 6(393), pp.2167-1168.
Bigstep. (2013). Low latency and big data.
Bing.com. (2021). value chain in big data in health care – Bing.
Dash, S., Shakyawar, S.K., Sharma, M. and Kaushik, S., 2019. Big data in healthcare: management, analysis, and future prospects. Journal of Big Data, 6(1), pp.1-25.
Galetsi, P., Katsaliaki, K. and Kumar, S., 2020. Big data analytics in the health sector: Theoretical framework, techniques, and prospects. International Journal of Information Management, 50, pp.206-216.
Guest Blogger (2011). The importance of structured data elements in EHRs. [online] Computerworld.
Guo, C. and Chen, J. (2019). Big Data Analytics in Healthcare: Data-Driven Methods for Typical Treatment Pattern Mining. Journal of Systems Science and Systems Engineering, [online] 28(6), pp.694–714
Journal Of AHIMA. (2018). Unstructured Data: An Important Piece of the Healthcare Puzzle | Journal Of AHIMA.
Ko, I. and Chang, H. (2017). Interactive Visualization of Healthcare Data Using Tableau. Healthcare Informatics Research, [online] 23(4), p.349.
Kulkarni, A.J., Siarry, P., Singh, P.K., Abraham, A., Zhang, M., Zomaya, A. and Baki, F. eds., 2020. Big Data Analytics in Healthcare. Springer.
Nittari, G., Khuman, R., Baldoni, S., Pallotta, G., Battineni, G., Sirignano, A., Amenta, F. and Ricci, G. (2020). Telemedicine Practice: Review of the Current Ethical and Legal Challenges. Telemedicine and e-Health, 26(12).
Rashik Rahman (2016). Heart Attack Analysis & Prediction Dataset. [online] Kaggle.com.
Skiba, D.J., 2014. The connected age: big data & data visualization. Nursing Education Perspectives, 35(4), pp.267-269.
COIT20253: Business Intelligence using Big Data.
Assessment 3
“Business Intelligence using Big Data.”
Practical and Written Assignment
This report contains big data statistics in health care and all the use cases and models that are applicable in the field of the medical sector. It contains the analysis of data and their use in real-world scenarios. We have analyzed the data using different tools to classify the data from patients, medical staff and observed that these data play an important role for different tools. We have different architectures that classify the data and the models on which the data are classified upon.
The examined apparatuses are useful to the specialists for conveying compelling medical care structures that work with start to finish medical services arrangements by improving patient results with the approach of huge information. Different websites and journal articles were visited to make this report and different points were summarized to make the report.
Table of Contents
2.2 Prescient examination and speedy analysis
2.4 Clinical exploration activities
2.6 Forecast of mass flare-ups
2.8 Constant wellbeing checking
3.0 Critical Analysis of Big Data Technologies
4.0 Use of Big Data tools on the dataset.
4.2 Adaptable looking and handling tools
4.4. Real-time and stream data processing tools
4.5 Visual data analytical tools
5.0 Critical Analysis of the Output
6.0 Big data Architecture Solution
6.1 Information Retrieval and Aggregation Modul
6.2 Communication/Integration APIs
6.3 Information Processing and Analysis Module
- INTRODUCTION
Data has been the way into a superior association and new turns of events. The more data we have, the more ideally, we can sort out ourselves to convey the best results. One such unique social need is medical services. Like other industries, medical care associations are delivering information at a huge rate that presents numerous benefits and difficulties simultaneously. In this report, we examine the fundamentals of huge information including its administration, investigation, and future possibilities particularly in the medical services area (Dash et al., 2019).
2.0 Big Data Use Cases
The critical difference between conventional methodologies and AI is that in AI, a model gains from models instead of being modified with rules. For a given errand, models are given as data sources (called highlights) and yields (called names). For example, digitized slides read by pathologists are changed over to highlights (pixels of the slides) and marks (e.g., data demonstrating that a slide contains proof of changes showing malignant growth). (Alvin, R., Dean, J. & Isaac, K. 2019).
Figure: Strategy Document
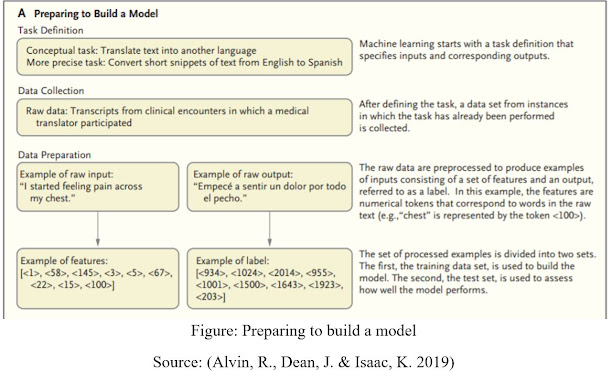
Figure: Preparing to build a model
Source: (Alvin, R., Dean, J. & Isaac, K. 2019)
With the information gathered during routine consideration, AI could be utilized to distinguish likely determinations during a clinical visit and bring issues to light of conditions that are probably going to show later. However, such methodologies have constraints. Less gifted clinicians may not inspire the data vital for a model to help them seriously, and the conclusions that the models are worked from might be temporary or incorrect, might be conditions that don’t show side effects (and hence may prompt overdiagnosis), might be impacted by billing, or may just not be recorded.
Models have effectively been effectively-prepared to reflectively distinguish anomalies across an assortment. Notwithstanding, just a predetermined number of imminent preliminaries include the utilization of AI models as a feature of a clinician’s ordinary course of work
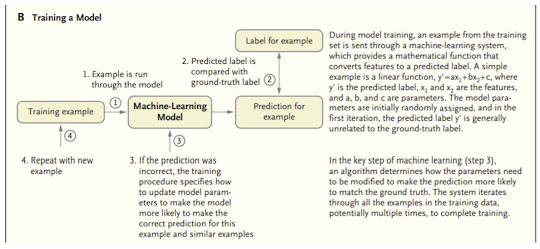
Figure: Training a Model for the prediction of the diseases
Source: (Alvin, R., Dean, J. & Isaac, K. 2019)
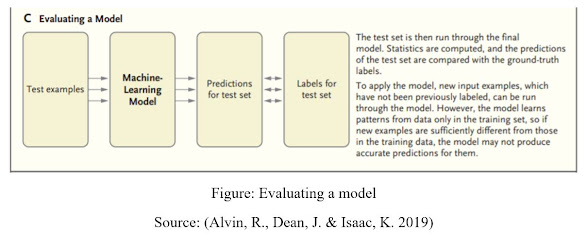
Figure: Evaluating a model
Source: (Alvin, R., Dean, J. & Isaac, K. 2019)
In an enormous medical care framework with a huge number of doctors treating a huge number of patients, there is variety in when and why patients present for care and how patients with comparable conditions are dealt with. A clear application is to analyze what is endorsed at the place of care with what a model predicts would be recommended, and errors could be hailed for audit (e.g., different clinicians will in general request another option treatment that reflects new rules). (Alvin, R., Dean, J. & Isaac, K. 2019).
Big Data Has different use cases.
· Illustrative investigation
· Demonstrative investigation
· Prescient examination
2.1 Prescriptive examination
As should be obvious, this is a sort of cycle that beginnings with the assurance of the issue to the arrangements on the best way to stay away from these difficulties later. Presently, ample opportunity has already past to glance through the techniques for utilizing Big Data investigation in the medical services field more decisively (ReferralMD, 2019).
2.2 Prescient examination and speedy analysis
Specialists from CSS Insight have asserted that the expense of wearable gadgets can become $25 billion before the finish of 2019. These days individuals use such gadgets as wellness trackers and smartwatches to gather and dissect data about their heartbeat and active work. In addition, there is a chance for the customers to send all gathered information straightforwardly to their family specialist.
2.3 Finance Management
AI can assist us with breaking down bills and assets. Therefore, we are offered a chance to lessen the number of slip-ups and misappropriations. Considering patients’ monetary capacities and their interest in assistance Big Data permits shaping value plans.
2.4 Clinical exploration activities
Clearly, this part is about prescient demonstrating in the advancement of new cures. Enormous Data devices and factual calculations can oversee clinical preliminaries. In this way, it’s simpler to select individuals to test new medications and discover better match medicines to singular patients. Incidentally, this innovation permits diminishing preliminary disappointments and speeding new medicines to advertise. Breaking down clinical preliminaries and patients records offer a chance to find unfavorable impacts before drugs arrive at the market.
2.5 Inventive plans of action
Obviously, Big information in medical care can bring you to benefit for the business. Information aggregators can give outsiders examined and gathered information blocks. There are a few thoughts. For example, if a drug organization needs to see or utilize clinical records of individuals that took a specific medication, it very well might be feasible to buy this data (ReferralMD, 2019).
2.6 Forecast of mass flare-ups
Large Data permits researchers to fabricate social models of populace wellbeing. As per them, specialists can make prescient models of flare-ups progress. These calculations can dissect infection episodes. Accordingly, specialists are offered a chance to make even more precisely focused on antibodies quicker.
2.7 Telemedicine
The advancement of online video gatherings, cell phones, remote gadgets, and wearables offers telemedicine a chance to furnish patients with clinical benefits on distance. These days medical services advancements are capable not exclusively to give an essential finding yet additionally to counsel patients and screen their wellbeing..
2.8 Constant wellbeing checking
Getting back to the wearable gadgets like wellness trackers and wristbands, it is imperative to underline their capacity to screen the soundness of their clients in a constant mode and give specialists data and changes. In this way, information from everything sensors can be investigated right away and, if something is not right, an alarm will be naturally shipped off the specialist or another trained professional.
3.0 Critical Analysis of Big Data Technologies
The data accumulated using the sensors can be made available on a limit cloud with pre-presented programming mechanical assemblies made by logical gadget creators. These gadgets would have data mining and ML limits made by AI experts to change over the information set aside as data into data. Upon execution, it would improve the capability of acquiring, taking care of, analyzing, and view of enormous data from clinical consideration. (Alvin, R., Dean, J. & Isaac, K. 2019).
The most notable stages for working the item framework that helps colossal data assessment are high power figuring bunches got to through cross-section preparing structures. Disseminated registering is such a structure that has virtualized limit advances and offers reliable kinds of help. It offers high unflinching quality, flexibility, and independence close by ubiquitous access, dynamic resource exposure, and composability. (Alvin, R., Dean, J. & Isaac, K. 2019).
3.1 Hadoop
Stacking a lot of (large) information into the memory of even the most impressive of processing groups is certifiably not a productive method to work with enormous information. Consequently, the best coherent methodology for breaking down gigantic volumes of complex enormous information is to appropriate and handle it in equal on various hubs.
When working with hundreds or thousands of hubs, one needs to deal with issues like how to parallelize the calculation, appropriate the information, and handle disappointments. One of the most famous open sources circulated applications for this design is Hadoop. Hadoop executes MapReduce calculation for preparing and creating enormous datasets. It productively parallelizes the calculation, handles disappointments, and timetables between machine correspondence across huge scope groups of machines. (Alvin, R., Dean, J. & Isaac, K. 2019).
3.2 Apache Spark
Apache Spark is another open-source option in contrast to Hadoop. It is a bound together motor for appropriated information preparing that incorporates more significant level libraries for supporting SQL questions (Spark SQL), streaming information (Spark Streaming), AI (MLlib), and chart handling (GraphX). These libraries help in expanding designer usefulness on the grounds that the programming interface requires lesser coding endeavors and can be flawlessly consolidated to make more kinds of complex calculations. By carrying out Resilient conveyed Datasets (RDDs), in-memory preparation of information is upheld that can make Spark about 100× quicker than Hadoop in the multi-pass investigation (on more modest datasets). (Alvin, R., Dean, J. & Isaac, K. 2019).
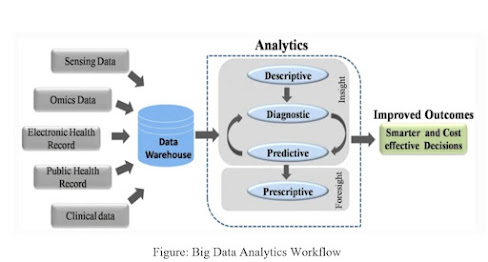
Figure: Big Data Analytics Workflow
Source: Dash et al., 2019.
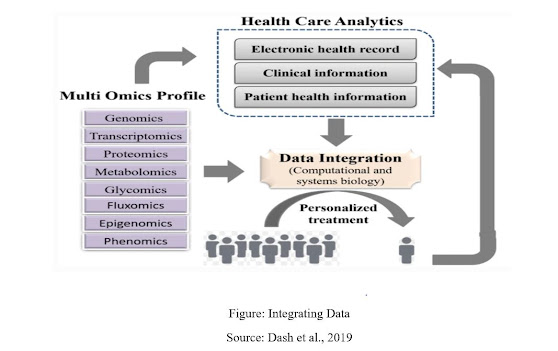
Figure: Integrating Data
Source: Dash et al., 2019
3.3 Spark Seq
An effective and cloud-prepared stage dependent on Apache Spark system and Hadoop library that is utilized for examinations of genomic information for intelligent genomic information investigation with nucleotide exactness.
3.4 SAMQA
Distinguishes mistakes and guarantees the nature of huge scope genomic information. This device was initially worked for the National Institutes of Health Cancer Genome Atlas undertaking to distinguish and report mistakes including arrangement/map [SAM] design blunder and void peruses.
3.5 Workmanship
It can re-enact profiles of reading mistakes and read lengths for information acquired utilizing high throughput sequencing stages including Solid and Illumina stages.
3.5 DistMap
Another toolbox utilized for conveyed short-read planning dependent on the Hadoop group that means to cover a more extensive scope of sequencing applications. For example, one of its applications to be specific the BWA mapper can perform 500 million read sets in around 6 h, roughly multiple times quicker than a regular single-hub mapper.
3.6 SeqWare
Question motor dependent on Apache HBase information base framework that empowers access for enormous scope entire genome datasets by incorporating genome programs and devices.
3.7 Deluge
An equal registering model is used in genome planning trials to improve the adaptability of perusing huge sequencing information.
3.8 Hydra
Utilizes the Hadoop-disseminated registering system for handling huge peptide and spectra information bases for proteomics datasets. This apparatus is equipped for performing 27 billion peptide scorings in under 60 min on a Hadoop group.
3.9 BlueSNP
R bundle dependent on Hadoop stage utilized for genome-wide affiliation contemplates (GWAS) investigation, essentially pointing to the measurable readouts to acquire huge relationship between genotype–aggregate datasets. The productivity of this device is assessed to dissect 1000 aggregates on 106 SNPs in 104 people in a length of thirty minutes.
3.10 Myrna
The cloud-based pipeline gives data on the articulation level contrasts of qualities, including reading arrangements, information standardization, and factual displaying.
3.11 Power BI
The motivation behind BI is to help in controlling the tremendous progression of business data inside and outside of the association by first distinguishing and afterward handling the data into consolidated and valuable administrative information and insight. BI assists associations with having the information and make determinations from significant information on business main considerations like guidelines and varieties underway, request, quality control, and the association’s interior components. A definitive objective of BI in any organization is to settle on ideal choices at all levels of the organization as effectively and rapidly as could be expected (Analytics Vidhya, 2021).
Figure: Data Visualization Using Power BI
4.0 Use of Big Data tools on the dataset.
Even though differentiated huge information systems are planned towards meeting explicit medical services targets, they, at the end of the day, arrange well for embracing standard structural rules for performing activities, for example, information gathering, pre-preparing, information examination, interpretation, and perception. Because of the space explicit nature of the enormous data healthcare system, experts, for example, information researchers should take the most extreme consideration in choosing fitting apparatuses to be utilized at each degree of the framework plan and execution. (Palanisamy and Thirunavukarasu, 2019).
4.1 Data Integration Tools
The nonstop development in the volume and speed of health care data with broadened information types requests the need of utilizing the administrations of information combination apparatuses for collecting information from disparate sources. Pentaho is a major information scientific stage that provides an end-to-end information mix to help clients for breaking down data from dissimilar sources like social data sets, Hadoop distributions, NoSQL stores, and undertaking applications. It likewise provides adaptable UI for making visual information streams to perform transformation and incorporation of data.
Palantir is an information coordination device that quickly melds data from divergent sources, for example, clinical gadget yields and medical codes. Further, it empowers logical strategies to create models for following a succession of methodology and clinical information measurements to manage medical services determination productively unites organized and unstructured (recordings, pictures, text, sound) healthcare information, numerical models, business rules to assemble predictive and prescriptive models (Palanisamy and Thirunavukarasu, 2019).
4.2 Adaptable looking and handling tools
Since a huge volume of clinical notes and unstructured content are commonly utilized by doctors in the medical services area, there is a colossal requirement for looking and ordering devices for performing improved full-text search capacity of clinical information. These tools are used for viable circulated text the board and indexing huge volumes of information in record frameworks like HDFS (Hadoop Distributed File System). Apache is an adaptable, elite indexing system that offers an incredible and precise full-text search facility for an assortment of utilization across various stages.
Google Dremel is a disseminated framework for interactively querying huge informational collections and supports settled information with column storage portrayal. It utilizes staggered execution trees for query preparing. Apache Drill is the Open-Source implementation of Google Dremel.
4.3 Machine Learning Tools
The medical care industry is sharp in profiting the applications of machine learning instruments to change the plentiful clinical data into noteworthy information by performing prescient and prescriptive investigation considering supporting wise clinical activities.
Sky tree is a general-purpose AI stage that utilizes fake intelligence to produce refined calculations for performing a progressed investigation. It can measure enormous datasets (structured and unstructured) in an exact way without downsampling. A few of its utilization cases are suggestion frameworks, irregularity/exception recognizable proof, prescient examination, grouping and market segmentation, and closeness search. A major information stage that mines and analyses the web, portable, sensor, and online media in Hadoop. AI stage provides a few instruments to perform AI assignments such as classification, relapse, group investigation, irregularity recognition, and association revelation.
4.4. Real-time and stream data processing tools
IoT and sensor gadgets found in the medical services area brief the information handling from broadened information sources to be done in a continuous way. The on-the-fly investigation of medical care information empowers the framework to settle on better choices for customizing patient-situated administrations.
4.5 Visual data analytical tools
Data visualization tools in healthcare help to identify patterns, trends, and deviations that include outliers, clusters, association discovery, and time series analysis for improving clinical delivery and public health policy reports, examination, and dashboards. It gives quick information perception on capacity stages like MongoDB, Cassandra, Redis, Riak, and CouchDB.
5.0 Critical Analysis of the Output
IBM Corporation is one of the greatest and experienced parts in this area to give medical care investigation benefits financially. IBM’s Watson Health is an AI stage to share and investigate wellbeing information among clinics, suppliers, and specialists. Additionally, Flatiron Health gives innovation situated administrations in medical services examination uncommonly engaged in malignant growth research.
5.1 Linguamatics
It is an NLP put-together calculation that depends with respect to an intelligent book mining calculation (I2E). I2E can separate and examine a wide exhibit of data. Results got utilizing this procedure are ten times quicker than different devices and do not need master information for information understanding. This methodology can give data on hereditary connections and realities from unstructured information. Traditional, ML requires well-curated information as a contribution to producing clean and sifted results. Notwithstanding, NLP when coordinated in EHR or clinical records essentially works with the extraction of perfect and organized data that regularly stays covered up with unstructured information.
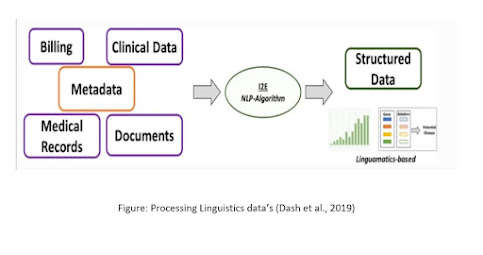
Figure: Processing Linguistics data’s (Dash et al., 2019)
5.2 IBM Watson
This is one of the one-of-a-kind thoughts of the tech-monster IBM that objectives huge information investigation in pretty much every expert area. This stage uses ML and AI-based calculations widely to separate the most extreme data from insignificant information. IBM Watson upholds the routine of incorporating a wide cluster of medical care areas to give significant and organized information While trying to reveal novel medication targets explicitly in the malignancy illness model, IBM Watson and Pfizer have framed useful cooperation to speed up the disclosure of novel safe oncology mixes.
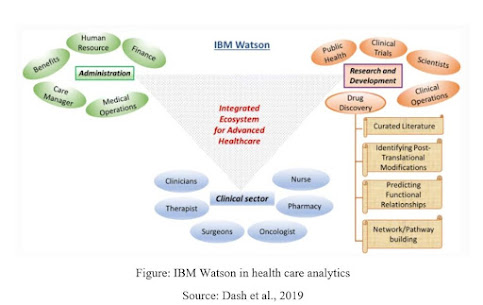
Figure: IBM Watson in health care analytics
Source: Dash et al., 2019
IBM Watson in medical services information investigation. Schematic portrayal of the different utilitarian modules in IBM Watson’s huge information medical services bundle. For example, the medication revelation area includes organization of profoundly planned information obtaining and examination inside the range of curating data set to building significant pathways towards explaining novel druggable targets.
5.3 Analysis of the Dataset
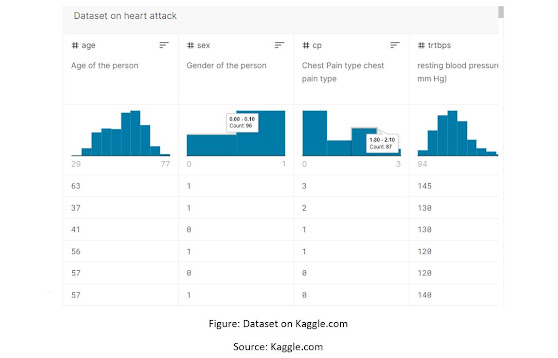
Figure: Dataset on Kaggle.com
Source: Kaggle.com
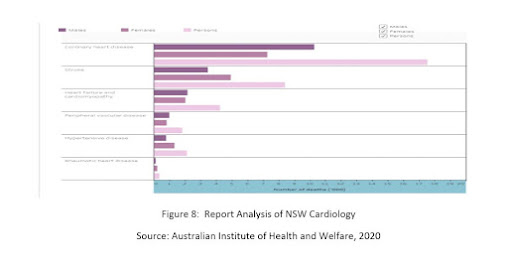
Figure 8: Report Analysis of NSW Cardiology
Source: Australian Institute of Health and Welfare, 2020
6.0 Big data Architecture Solution
DataCare’s engineering contains three primary modules: the first supervises recovering and amassing the data created in the wellbeing focus or clinic, the subsequent will measure and examine the information, and the third shows the important data in a dashboard, permitting the coordination with outer data frameworks.
6.1 Information Retrieval and Aggregation Module
AdvoCare is the arrangement of equipment and programming instruments intended to oversee interchanges among patients and medical care staff.
• Sensors estimating some current worth or status either in a nonstop or intermittent style and sending it to Buslogic or Advant Control workers; like thermometers or commotion or light sensors.
• Assistance gadgets, for example, fastens or pull controllers that are actioned by the patients and send the help call to the
• Voice and video correspondence frameworks that send and get data from different gadgets or from Jitsi (SIP Communicator), which are taken care of by EasyConf.
• Data securing frameworks worked through graphical client interfaces in gadgets like tablets, e.g., studies or other data frameworks.
• Planned visits: medical care faculty will intermittently visit certain rooms or patients as a piece of a pre-setup arrangement.
• Assistance errands: medical caretakers and nursing colleagues should perform certain errands as a reaction to a help call.
• Patients’ fulfillment: the main help quality emotional metric is the patients’ fulfillment, which is gotten by means of reviews.
6.2 Communication/Integration APIs
Information can be recovered from AdvantCare workers through SOAP web administrations, which will be utilized in those solicitations that require high preparing limits and are stateless. Additionally, the data can be gotten to by means of a REST API, where the calls are performed through HTTP solicitations, and information is traded in JSON-serialized design
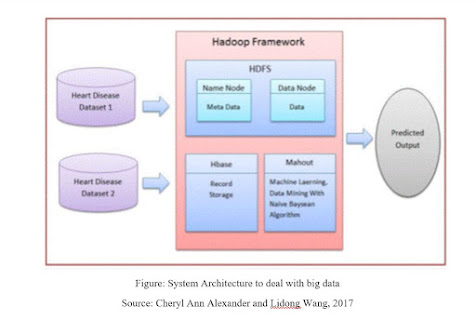
Figure: System Architecture to deal with big data
Source: Cheryl Ann Alexander and Lidong Wang, 2017
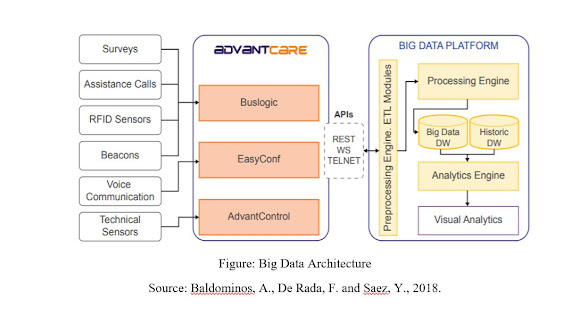
Figure: Big Data Architecture
Source: Baldominos, A., De Rada, F. and Saez, Y., 2018.
6.3 Information Processing and Analysis Module
The Data Processing and Analysis Module is important for a Big Data stage dependent on Apache Spark, which permits a coordinated climate for the turn of events and abuse of continuous gigantic information examination, beating different arrangements like Hadoop MapReduce or Storm, scaling out up to 10,000 hubs, giving issue resistance and permitting inquiries utilizing a SQL-like language.
This module includes four unique frameworks: Preprocessing Engine, Processing Engine, Big Data, and Historic Data Distribution centers, and Analytics Engine.
6.4 Pre-processing Engine
This framework plays out the ETL (Extract-Transform-Load) measures for the AdvantCare information. It will initially speak with AdvantCare utilizing the accessible APIs to recover the information, which will be later changed into an appropriate configuration to be acquainted with the Processing Motor. As a result of the metadata given by AdvantCare, the data can be grouped to facilitate its examination. The standardized and combined information will be put away in MongoDB, the main free and open-source record arranged data set, where assortments will store information for ongoing examination just as notable information to help group examination to register the advancement of various measurements on schedule. This framework runs over the Spark processing bunch and manages information solidification measures for occasionally conglomerating information, too as to help the caution and proposal subsystems.
6.5 Data Warehouses
Information separated by the Pre-processed Engine and improved by the Handling Engine will be put away in the Big Data Warehouse, which will store ongoing data. Also, the Historic Data Warehouse stores accumulated notable information, which will be utilized by the Analytics Motor to distinguish recent fads or pattern shifts for the distinctive quality measurements.
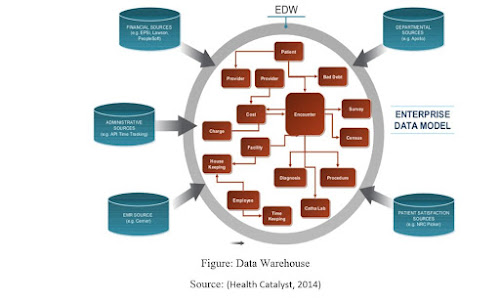
Figure: Data Warehouse
Source: (Health Catalyst, 2014)
6.6 Analytics Engine
This framework runs the clump measures that will apply the factual investigation strategies, just as AI calculations over Realtime Big Data. Alongside the notable information, time arrangement and ARIMA (autoregressive coordinated moving normally) strategies gives an analysis of the worldly conduct of the model. This motor to executes a Bayes-based early alarms framework (EAS) ready to distinguish and foresee a decline in the assistance quality or productivity measurements under a pre-set edge, which will be informed by means of push or email notices.
7.0 Conclusion
This report offers the most recent data on Big Data investigation in medical care, anticipating coronary failure, also, fitting clinical treatment to the person. The outcomes will manage suppliers, medical services associations, attendants, what is more, other treatment suppliers in utilizing Big Data advancements to anticipate and oversee cardiovascular failure just as what protection concerns face the utilization of Big Data investigation in medical care. Compelling and customized clinical treatment can be created utilizing these advances (Cheryl Ann Alexander and Lidong Wang, 2017). I have used Hadoop and Apache spark to analyze my data to map them into real data statistics and we can further use this data to make a comparison, how different health sectors are performing.
References
Analytics Vidhya (2021). Microsoft Power BI | Rise of Microsoft Power BI as a Data Analytics Tool.Analytics Vidhya.
Alvin, R., Dean, J. & Isaac, K. 2019, “Machine Learning in Medicine”, The New England journal of medicine, vol. 380, no. 14, pp. 1347-1358.
Baldominos, A., De Rada, F. and Saez, Y., 2018. DataCare: Big Data Analytics Solution for Intelligent Healthcare Management. International Journal of Interactive Multimedia & Artificial Intelligence, 4(7).
Cheryl Ann Alexander and Lidong Wang (2017). Big Data Analytics in Heart Attack Prediction.
Dash, S., Shakyawar, S.K., Sharma, M. and Kaushik, S. (2019). Big data in healthcare: management, analysis, and future prospects. Journal of Big Data,
Health Catalyst (2014). What is the best Healthcare Data Warehouse Model for Your Organization? viewed on 4 Jun 2021 Slideshare.net.
Palanisamy, V. and Thirunavukarasu, R. (2019). Implications of big data analytics in developing healthcare frameworks – A review. Journal of King Saud University – Computer and Information Sciences.
ReferralMD. (2019). Use Cases for Big Data in Healthcare.
